The beautiful hash algorithm
Cryptography deals with the protection of data through the process of encryption and decryption. Spurred by the massive proliferation of hardware and software of the 4th industrial revolution, cryptography now plays a key role in our modern digital world. The need to ensure integrity, confidentiality and authenticity of distributed data has never been greater.
One of the workhorses of modern cryptography are cryptographic hash functions.
The goal of this post is to briefly explain how cryptographic hash functions work, to show some examples of where they are utilised in modern cryptography, and to help you gain an appreciation of the beautiful and efficient way in which they operate.
Please note: throughout this post, the examples given use the SHA-256 hash algorithm, which is a member of the SHA-2 family of cryptographic hash functions designed by the United States National Security Agency. The SHA-2 family (SHA stands for ‘Secure Hash Algorithm’) consists of six hash functions with digests (hash values) that are 224, 256, 384 or 512 bits. Wherever the SHA-256 examples appear, in your mind you can think of any of the SHA-2 members.
So what are cryptographic hashes and why are they useful?
In mathematics, a hash function is one that can be used to map data of arbitrary size to data of fixed size.
A cryptographic hash function is a special class of hash function, operating on binary data (1’s and 0’s) and providing a unique and fixed-length fingerprint of binary data of any arbitrary size. This proves to be extremely useful whenever the assurance of data integrity is needed.
The ideal cryptographic hash function has five main properties:
- it is deterministic, meaning the same message will always result in the same hash value.
- it is efficient, meaning the hash function is capable of returning the hash of an input quickly.
- it is one-way, meaning that it’s computationally infeasible to derive the original message (the pre-image) from its hash value. In other words, given a hash, it should be extremely difficult to retrace the deterministic steps taken to reproduce the pre-image of that hash.
- It is collision resistant, meaning it is computationally infeasible to find two different messages with the same hash value. More on this topic below.
- Any small change to the message results in a large change in the resulting hash value.
Some examples of SHA-256 hashes

What is collision resistance and why is it important?
Collision resistance dictates that it should be extremely hard to find or generate two different messages (M, M’) such that Hash(M) == Hash(M’).
Collision resistance is very important, because without it, the whole usefulness of a hash function is completely lost. If an attacker is able to create collisions, they can pass off malicious files or data as having a valid hash, and thereby as being legitimate.
As it turns out, collision resistance is very difficult to achieve. Think about it for a moment. The possible combinations of 1’s and 0’s of all the messages we could possibly hash is almost infinite. However, the possible combination of 1’s and 0’s that a hash function can produce is a very finite number. In the case of SHA-256 — which has a 256-bit digest — the number of possible hash combinations is 2²⁵⁶.
Yes, that’s a very big number, but not nearly as big as the pool of potential message bits that we could hash.
So, many more possible message combinations than possible hash combinations. This means that by the pigeonhole principle there MUST be many collisions that exist on SHA-256!
So if we know for a fact that many collisions exist for any SHA-256 hash, how easy are they to find?!
To answer this question, we need to visit some algebraic theory.
The birthday paradox and finding collisions on hash functions.
If you get a group of 100 people in a room, and start asking each of them in turn their birthday (ignoring gap years), it turns out that after asking just 23 people, you have a 50% chance of two or more individuals having a birthday on the same day.
After having asked 30 people, the chance of a birthday collision would have risen to 70%.
After having asked 70 people, the chance of a birthday collision would have risen to 99.99%.
It may well seem surprising that a group of just 23 individuals is required to reach a 50% probability of a birthday collision. But thinking about it, each individual in the group of 23 is matched with 22 other individuals, meaning that in total we do 253 comparisons (23 × 22/2). This is well over half the number of days in a year — 183.
This birthday paradox allows us to launch what is called a birthday attack, in which we find a collision for a hash function.
With a birthday attack, it is possible to find a collision on an n-bit hash function after approximately sqrt 2^n attempts.
By way of example, for a 64-bit hash, there are approximately 1.8 × 10¹⁹ different outputs. If these are all equally probable, then it would take approximately 5 billion attempts (5.38 × 10⁹) to generate a collision using brute force. This value is called hash algorithm’s ‘birthday bound’.
What this implies is that in order to make a birthday attack computationally infeasible, modern hash algorithms MUST produce digests that are larger than a specific threshold.
64 bit hashes are clearly too short, and can be compromised. But even longer hashes have also been proven vulnerable. In 2008, researchers were able to do find a collision on the MD5 hash algorithm (128 bit digest) after ~2²²¹ hashes. In 2017, Google researchers found a collision on SHA 1 (160 bit digest) after ~2²⁶¹ hashes.
As yet there are no known efficient algorithms that exist for finding collisions on the SHA-256 hash. The best one could do would be a brute-force birthday attack on this function, which would require on average 40³⁸ hashes. Since executing a brute-force attack of this size is considered computationally infeasible, SHA-256 can be considered collision-resistant, for now at least.

The inner workings of SHA-256 explained
Given the stringent requirements for an effective hash function, SHA-256 performs pretty well. But how does it do this?
SHA-256 is built using the Merkle–Damgård structure, from a one-way compression function itself built using the Davies–Meyer structure from a specialised block cipher called SHACAL-2.
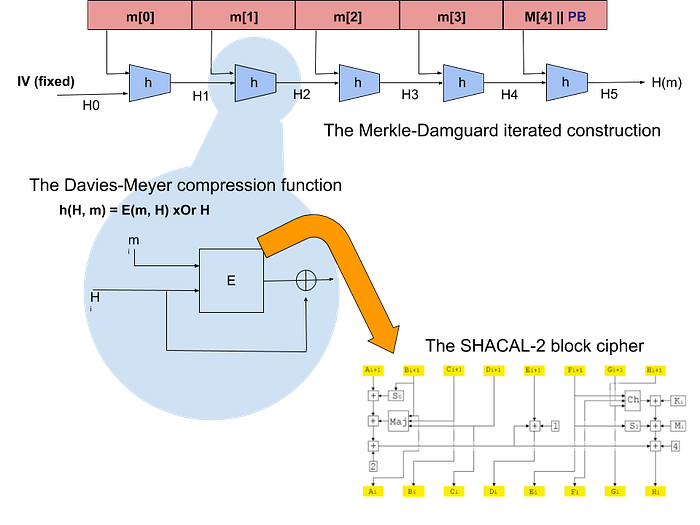
First, the message to be hashed is broken into fixed-length blocks of 1’s and 0’s (m[0], m[1], m[2]…) and a fixed initialisation vector IV is used.
A compression function h (explained later) is applied to the first message block, along with the IV.
What results from that is called a chaining variable H1 , which is fed into the next compression function h, along with the next block of the message m[1].
This compresses both inputs into another chaining variable H2, which is used as input to the next compression function, and so on and so forth.
This hashing chain continues until the final message block is reached, which is appended with a padding block PB (containing information on the message length). This block, together with the second-to-last chaining variable, is fed into the final compression function, and the output thereof is the actual hash returned — H(m).
This construction works well, because theory tells us that if the little compression function h is collision-resistant, then the big Merkle-Damgård hash function is ALSO collision resistant. Nice.
The collision-resistant compression function h is derived from the Davies-Meyer construction, described as follows: given the message block m and the chaining variable H, the chaining variable is encrypted using a block cipher E, with the message block being used as the key. The result is then bitwise Or’d with the chaining variable H.
The underlying block cipher of the encryption function E is SHACAL-2, which uses a 512-bit key (taken from the message block), with a 256-bit block (which corresponds to the chaining variables in the Merkle-Damguard paradigm). This block cipher uses confusion and diffusion to permute and swap bits around.
Theory also tells us that if we use an ‘ideal’ cipher for the block cipher E, this construction is as collision resistant as possible. In other words finding a collision for the compression function h requires the adversary to evaluate the encryption function on average 2^n/2 times. But as we’ve seen above, that’s the same as the generic birthday attack. As far as we know, the SHACAL-2 block cipher meets the requirements of being an ideal block cipher, meaning SHA-256 is as collision resistant as it possibly can be.
OK, enough theory. Let’s see the beautiful hash algorithm in action.
Some practical uses of hashing functions
- Signature generation and verification
A digital signature is a mathematical scheme for verifying the authenticity of digital messages or documents. Unlike handwritten signatures (which are easy to forge) digital signatures — if implemented correctly — are very difficult to forge and provide assurances of the origin, identity and content of an electronic document, transaction or message.
Digital signatures are used extensively in communication protocols such as in email and internet communication to ensure data integrity and authenticity.
Digital signatures are based on public key cryptography, also known as asymmetric cryptography. Using a public key algorithm, one can generate two keys that are mathematically linked: one private and one public.
Private and public keys are mutually authenticating — the individual creating the digital signature uses their own private key to encrypt signature-related data, and the only way to decrypt that data (and authenticate the digital signature) is with the signer’s public key.
But where do hashes fit into this? To create a digital signature, the signing algorithm generates a hash of electronic data to be signed. The private key is then used to encrypt the resulting hash. The encrypted hash — along with some other useful information, such as the hashing algorithm used — is the digital signature.
The reason for encrypting the hash instead of the entire message or document is that, as we’ve seen, a hash function can convert an arbitrary input into a fixed length value, which is usually much shorter. This saves time because hashing is much faster than signing.
The value of a hash is unique to the hashed data. Any change in the data, even a change in a single character, will result in a different hash value (see property number 5 above).
If the decrypted hash matches the computed hash of the same data, it proves that the data hasn’t changed since it was signed. If the two hashes don’t match, the data has either been tampered with in some way, or the signature was created with a private key that doesn’t correspond to the public key presented by the signer.
2. Password verification and protection
If you read tech news, you’re probably aware that digital mega-breaches happen at an alarming scale. It seems that no system is 100% safe these days. In this dystopian reality we find ourselves living it, securing sensitive and important user data is as high a priority as ever.

OK sure, we must never store passwords in plain text. But then how then can one verify a user’s password, whilst at the same time keeping data safe and secure from breaches?
Using a hash algorithm like SHA-256, one could store the hash of the users password in the database. Since SHA-256 is deterministic, one way and collision-resistant (see its properties above), it’s a great way of validating users’ credentials whilst not requiring the storing of their private data in clear text. When a user enters their password on the website, your backend code simply hashes the user-inputted value, and compares it to the hashed value stored in the database for their record. If they match, the password is correct.
It’s very important to note, however, that hashing passwords by itself does not provide an iron-clad security against data breaches. Firstly, birthday-attack-resistant hashes should always be used (so avoid MD5 and SHA1) and passwords should always be hashed with a salt (random data added to a password [and stored alongside the password], to provide an extra layer of entropy and randomness).
Also, one should consider using a function like Bcrypt which uses well-tested password-based key derivation functions, configurable to remain slow and resistant to brute-force attacks even as computational power increases.
The 177 million LinkedIn accounts stolen in 2012 had actually been hashed, but using SHA1 without extra protections like a salt. Almost all the hashed passwords were cracked. HOW? Hackers couldn’t reverse a hashed password created with a function like SHA1. But because the passwords weren’t salted, they could take a huge list of common passwords (letmein, password123, qwerty etc.), hash the values, and compare to the stolen hashed passwords to find matches.
So, follow best principles and always salt your hashed passwords.
3. Subresource Integrity
2018 saw a slew of insidious card skimming attacks against over 800 e-commerce sites around the world, including profile websites such as British Airways, TicketMaster and VisionDirect.
The party responsible was Magecart, a hacker group specialising in skimming credit card details from payment forms on websites. The group has become so infamous they’re in danger of becoming a household name.
Traditionally, card skimming has occurred at ATMs, card machines, and other machines where people pay using credit cards, with the objective of stealing credit card data for nefarious means.
But that’s all very 1992. These Magecart baddies skim card details digitally, through code inserted into websites.
To achieve this, they have targeted Content Delivery Networks (CDNs). CDNs are sites that host files such as scripts and stylesheets that are shared among multiple sites can improve site performance and conserve bandwidth. This convenience comes at a risk, however: if an attacker gains control of a CDN, the attacker can inject arbitrary malicious content into files on the CDN (or replace the files completely) and can thereafter potentially attack all sites that fetch files from that CDN.
This is what Magecart did. In the case of Ticketmaster (who was not directly compromised or breached themselves), Magecart compromised a third-party supplier for their website known as Inbenta. Magecart actors breached Inbenta’s systems and either added to or completely replaced a custom JavaScript module Inbenta made for Ticketmaster with their own digital skimmer code.
The target for Magecart actors was the payment information entered into forms on Ticketmaster’s various websites.
So how do we protect our websites from these terrible attacks? Hashing to the rescue.
Subresource Integrity (SRI) is a security feature in modern browsers that enables browsers to verify that resources they fetch (for example, from a CDN) are delivered without unexpected manipulation. It works by allowing you to provide a cryptographic hash that a fetched resource must match.
If the content of the resource is altered or compromised in any way, the calculated hash value of the new contents will not match that of the hash provided.
SubResource Integrity enables you to mitigate some risks of attacks such as this, by ensuring that the files your web application or web document fetches (from a CDN or anywhere) have been delivered without a third-party having injected any additional content into those files — and without any other changes of any kind at all having been made to those files.
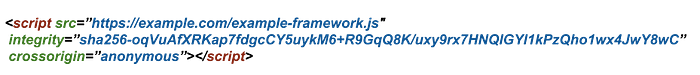
When a browser encounters a <script> or <link> element with an integrity attribute, before executing the script or before applying any stylesheet specified by the <link> element, the browser will first compare the script or stylesheet to the expected hash given in the integrity value.
4. The BlockChain

OK I know you’re sick and tired of Medium posts about the blockchain. But since hashing is a fundamental component of the blockchain paradigm, and armed with what we now know about hash algorithms, a large part of this hitherto confusing-as-hell paradigm suddenly becomes a lot easier to understand.
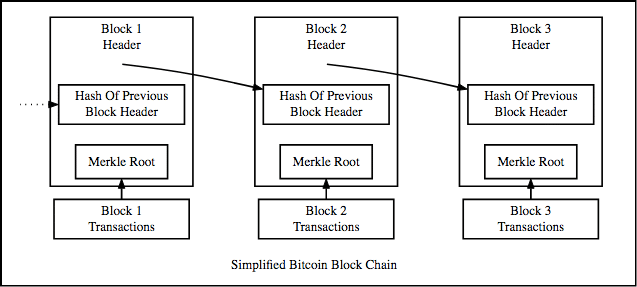
At its essence, the blockchain is a sequence of blocks, each containing data which is linked to the next block via a hash pointer, thereby creating a chained list of blocks. Aha, hence the name blockchain.
So what is a hash pointer? A hash pointer is similar to a pointer, but instead of just containing the address of the previous block it also contains the hash of the data inside the previous block. What this means is that none of the previous blocks cannot be tampered with, without affecting the hash value of that block.
Imagine a hacker attacks block 3 and tries to change the data. As we’ve seen earlier, a slight change in data changes the resulting hash drastically. This means that even the slightest change in block 3, will change the hash which is stored in block 4, which in turn will change the data and the hash of block 4, thereby changing the hash value in block 5, and so on and so forth. This is exactly how blockchains attain immutability.
This system of hashing guarantees that no transaction in the history can be tampered with because if any single part of the transaction changes, so does the hash of the block to which it belongs, and any following blocks’ hashes as a result.
The mind-blowing result is that the potentially infinite state of the blockchain can be represented as a single 256 bit hash string at the top of the Merkle Tree which all distributed nodes can reach consensus on.
Conclusion and looking ahead
The field of cryptography is continuously evolving, and a newer family of SHA called SHA-3 has already been approved by NIST, and is presumably ready to become the de facto standard should significant attacks on SHA-2 ever be successfully demonstrated.
There is also the ever-looming threat of quantum computing, although signs are that hash functions like SHA-2 will hold up well against quantum computers.
I hope the few examples above have given an idea of just how useful and crucially important cryptographic hashes are. It’s safe to say they underpin many of the protocols and processes that keep the heart of the modern digital economy beating. And as cloud computing and distributed computing become all-pervasive, their importance will only grow.
